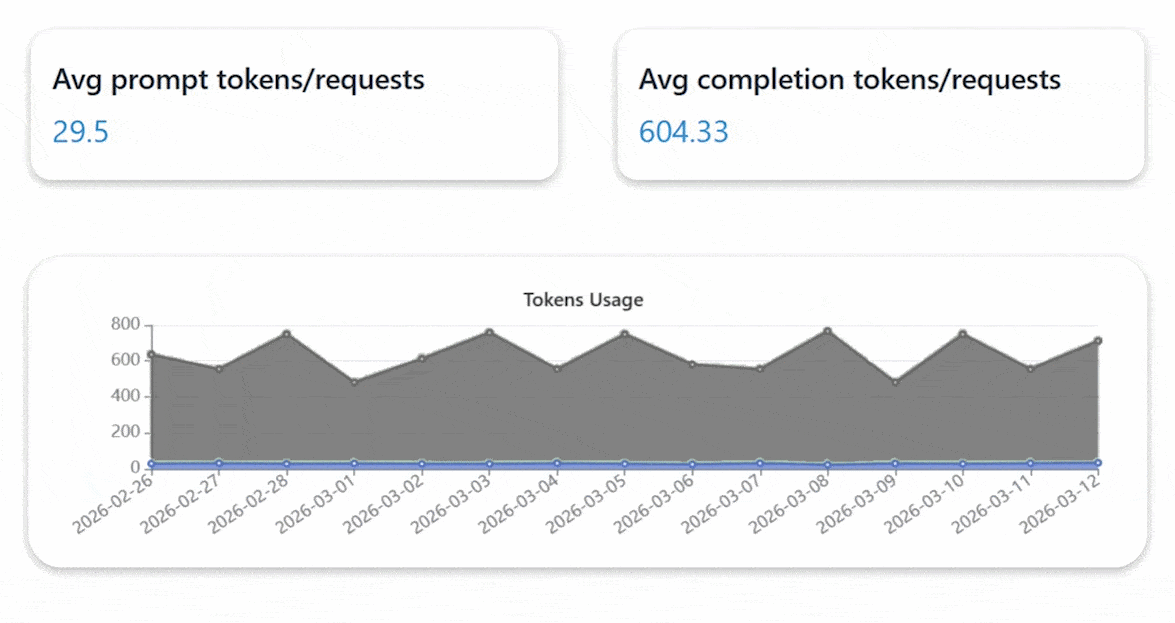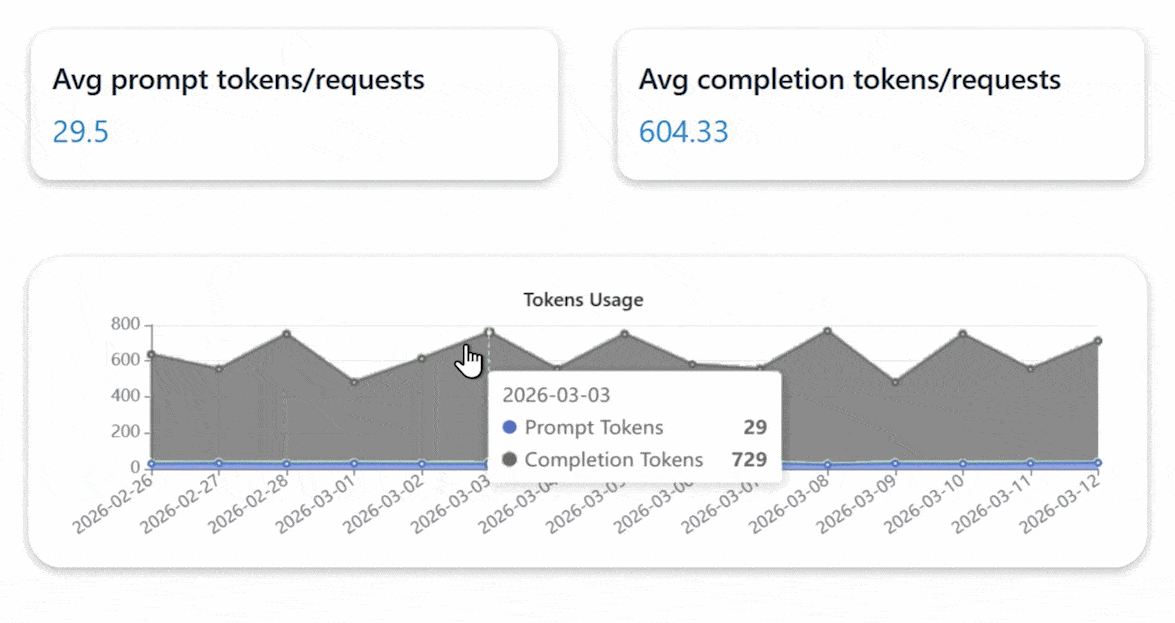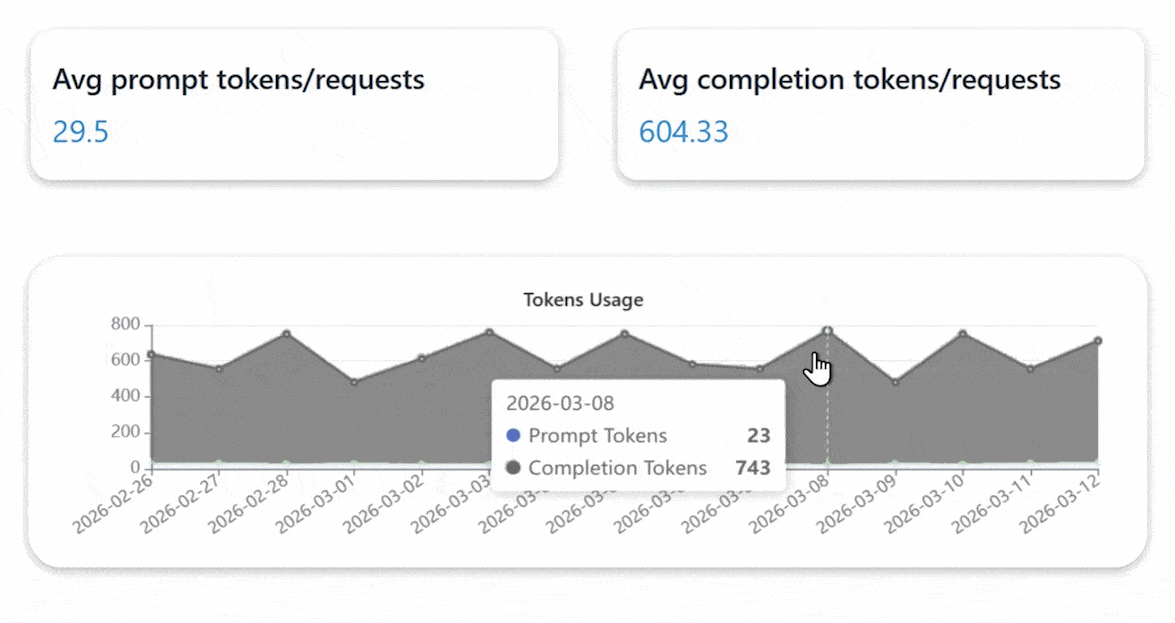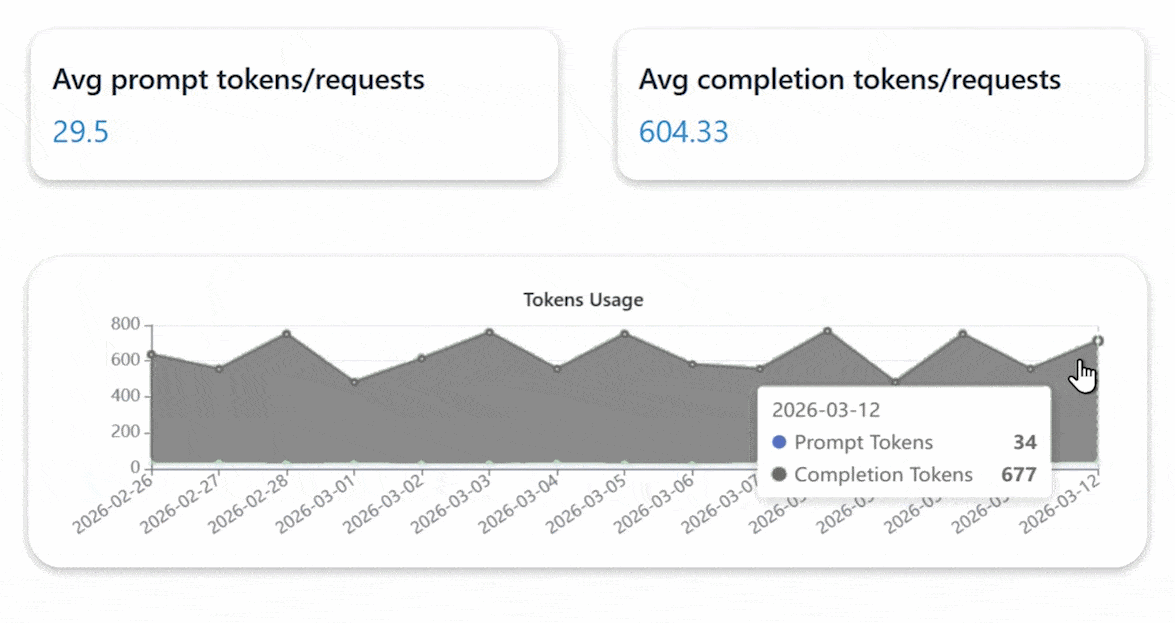





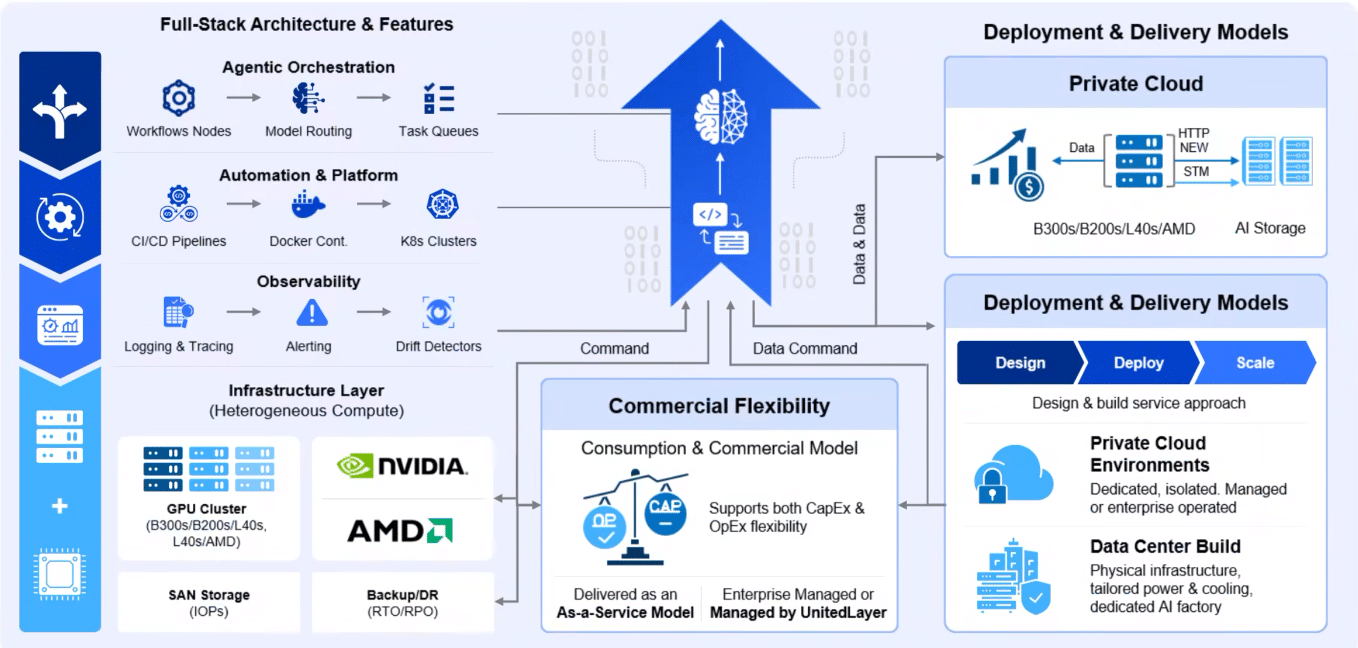


Enterprise Private Cloud with Private AI
Enterprise Private Cloud with Private AI: Built for Control, Intelligence, and Business Impact Enterprise cloud strategy is entering a new era. For years, organizations adopted cloud to improve agility, scalability, and speed. But as…


















































